Forest Cover Type Classification with XGBoost (Original Version)#
Dataset: Forest Cover Type Kaggle
# Core libraries
import pandas as pd
import numpy as np
# Visualization
import matplotlib.pyplot as plt
# Machine learning
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.metrics import (
accuracy_score,
f1_score,
precision_score,
recall_score,
classification_report,
confusion_matrix,
ConfusionMatrixDisplay
)
from xgboost import XGBClassifier
# Utility
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("../data/forestcover.csv")
print(df.columns.tolist())
['Elevation', 'Aspect', 'Slope', 'Horizontal_Distance_To_Hydrology', 'Vertical_Distance_To_Hydrology', 'Horizontal_Distance_To_Roadways', 'Hillshade_9am', 'Hillshade_Noon', 'Hillshade_3pm', 'Horizontal_Distance_To_Fire_Points', 'Wilderness_Area1', 'Wilderness_Area2', 'Wilderness_Area3', 'Wilderness_Area4', 'Soil_Type1', 'Soil_Type2', 'Soil_Type3', 'Soil_Type4', 'Soil_Type5', 'Soil_Type6', 'Soil_Type7', 'Soil_Type8', 'Soil_Type9', 'Soil_Type10', 'Soil_Type11', 'Soil_Type12', 'Soil_Type13', 'Soil_Type14', 'Soil_Type15', 'Soil_Type16', 'Soil_Type17', 'Soil_Type18', 'Soil_Type19', 'Soil_Type20', 'Soil_Type21', 'Soil_Type22', 'Soil_Type23', 'Soil_Type24', 'Soil_Type25', 'Soil_Type26', 'Soil_Type27', 'Soil_Type28', 'Soil_Type29', 'Soil_Type30', 'Soil_Type31', 'Soil_Type32', 'Soil_Type33', 'Soil_Type34', 'Soil_Type35', 'Soil_Type36', 'Soil_Type37', 'Soil_Type38', 'Soil_Type39', 'Soil_Type40', 'Cover_Type']
# Make column names consistent and Python-friendly
df.columns = (
df.columns
.str.strip()
.str.lower()
.str.replace(" ", "_")
.str.replace("-", "_")
)
print(df.columns.tolist())
['elevation', 'aspect', 'slope', 'horizontal_distance_to_hydrology', 'vertical_distance_to_hydrology', 'horizontal_distance_to_roadways', 'hillshade_9am', 'hillshade_noon', 'hillshade_3pm', 'horizontal_distance_to_fire_points', 'wilderness_area1', 'wilderness_area2', 'wilderness_area3', 'wilderness_area4', 'soil_type1', 'soil_type2', 'soil_type3', 'soil_type4', 'soil_type5', 'soil_type6', 'soil_type7', 'soil_type8', 'soil_type9', 'soil_type10', 'soil_type11', 'soil_type12', 'soil_type13', 'soil_type14', 'soil_type15', 'soil_type16', 'soil_type17', 'soil_type18', 'soil_type19', 'soil_type20', 'soil_type21', 'soil_type22', 'soil_type23', 'soil_type24', 'soil_type25', 'soil_type26', 'soil_type27', 'soil_type28', 'soil_type29', 'soil_type30', 'soil_type31', 'soil_type32', 'soil_type33', 'soil_type34', 'soil_type35', 'soil_type36', 'soil_type37', 'soil_type38', 'soil_type39', 'soil_type40', 'cover_type']
print(df.shape)
print(df.dtypes)
print(df.info())
print(df.describe().T)
(581012, 55)
elevation int64
aspect int64
slope int64
horizontal_distance_to_hydrology int64
vertical_distance_to_hydrology int64
horizontal_distance_to_roadways int64
hillshade_9am int64
hillshade_noon int64
hillshade_3pm int64
horizontal_distance_to_fire_points int64
wilderness_area1 int64
wilderness_area2 int64
wilderness_area3 int64
wilderness_area4 int64
soil_type1 int64
soil_type2 int64
soil_type3 int64
soil_type4 int64
soil_type5 int64
soil_type6 int64
soil_type7 int64
soil_type8 int64
soil_type9 int64
soil_type10 int64
soil_type11 int64
soil_type12 int64
soil_type13 int64
soil_type14 int64
soil_type15 int64
soil_type16 int64
soil_type17 int64
soil_type18 int64
soil_type19 int64
soil_type20 int64
soil_type21 int64
soil_type22 int64
soil_type23 int64
soil_type24 int64
soil_type25 int64
soil_type26 int64
soil_type27 int64
soil_type28 int64
soil_type29 int64
soil_type30 int64
soil_type31 int64
soil_type32 int64
soil_type33 int64
soil_type34 int64
soil_type35 int64
soil_type36 int64
soil_type37 int64
soil_type38 int64
soil_type39 int64
soil_type40 int64
cover_type int64
dtype: object
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 581012 entries, 0 to 581011
Data columns (total 55 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 elevation 581012 non-null int64
1 aspect 581012 non-null int64
2 slope 581012 non-null int64
3 horizontal_distance_to_hydrology 581012 non-null int64
4 vertical_distance_to_hydrology 581012 non-null int64
5 horizontal_distance_to_roadways 581012 non-null int64
6 hillshade_9am 581012 non-null int64
7 hillshade_noon 581012 non-null int64
8 hillshade_3pm 581012 non-null int64
9 horizontal_distance_to_fire_points 581012 non-null int64
10 wilderness_area1 581012 non-null int64
11 wilderness_area2 581012 non-null int64
12 wilderness_area3 581012 non-null int64
13 wilderness_area4 581012 non-null int64
14 soil_type1 581012 non-null int64
15 soil_type2 581012 non-null int64
16 soil_type3 581012 non-null int64
17 soil_type4 581012 non-null int64
18 soil_type5 581012 non-null int64
19 soil_type6 581012 non-null int64
20 soil_type7 581012 non-null int64
21 soil_type8 581012 non-null int64
22 soil_type9 581012 non-null int64
23 soil_type10 581012 non-null int64
24 soil_type11 581012 non-null int64
25 soil_type12 581012 non-null int64
26 soil_type13 581012 non-null int64
27 soil_type14 581012 non-null int64
28 soil_type15 581012 non-null int64
29 soil_type16 581012 non-null int64
30 soil_type17 581012 non-null int64
31 soil_type18 581012 non-null int64
32 soil_type19 581012 non-null int64
33 soil_type20 581012 non-null int64
34 soil_type21 581012 non-null int64
35 soil_type22 581012 non-null int64
36 soil_type23 581012 non-null int64
37 soil_type24 581012 non-null int64
38 soil_type25 581012 non-null int64
39 soil_type26 581012 non-null int64
40 soil_type27 581012 non-null int64
41 soil_type28 581012 non-null int64
42 soil_type29 581012 non-null int64
43 soil_type30 581012 non-null int64
44 soil_type31 581012 non-null int64
45 soil_type32 581012 non-null int64
46 soil_type33 581012 non-null int64
47 soil_type34 581012 non-null int64
48 soil_type35 581012 non-null int64
49 soil_type36 581012 non-null int64
50 soil_type37 581012 non-null int64
51 soil_type38 581012 non-null int64
52 soil_type39 581012 non-null int64
53 soil_type40 581012 non-null int64
54 cover_type 581012 non-null int64
dtypes: int64(55)
memory usage: 243.8 MB
None
count mean std \
elevation 581012.0 2959.365301 279.984734
aspect 581012.0 155.656807 111.913721
slope 581012.0 14.103704 7.488242
horizontal_distance_to_hydrology 581012.0 269.428217 212.549356
vertical_distance_to_hydrology 581012.0 46.418855 58.295232
horizontal_distance_to_roadways 581012.0 2350.146611 1559.254870
hillshade_9am 581012.0 212.146049 26.769889
hillshade_noon 581012.0 223.318716 19.768697
hillshade_3pm 581012.0 142.528263 38.274529
horizontal_distance_to_fire_points 581012.0 1980.291226 1324.195210
wilderness_area1 581012.0 0.448865 0.497379
wilderness_area2 581012.0 0.051434 0.220882
wilderness_area3 581012.0 0.436074 0.495897
wilderness_area4 581012.0 0.063627 0.244087
soil_type1 581012.0 0.005217 0.072039
soil_type2 581012.0 0.012952 0.113066
soil_type3 581012.0 0.008301 0.090731
soil_type4 581012.0 0.021335 0.144499
soil_type5 581012.0 0.002749 0.052356
soil_type6 581012.0 0.011316 0.105775
soil_type7 581012.0 0.000181 0.013442
soil_type8 581012.0 0.000308 0.017550
soil_type9 581012.0 0.001974 0.044387
soil_type10 581012.0 0.056168 0.230245
soil_type11 581012.0 0.021359 0.144579
soil_type12 581012.0 0.051584 0.221186
soil_type13 581012.0 0.030001 0.170590
soil_type14 581012.0 0.001031 0.032092
soil_type15 581012.0 0.000005 0.002272
soil_type16 581012.0 0.004897 0.069804
soil_type17 581012.0 0.005890 0.076518
soil_type18 581012.0 0.003268 0.057077
soil_type19 581012.0 0.006921 0.082902
soil_type20 581012.0 0.015936 0.125228
soil_type21 581012.0 0.001442 0.037950
soil_type22 581012.0 0.057439 0.232681
soil_type23 581012.0 0.099399 0.299197
soil_type24 581012.0 0.036622 0.187833
soil_type25 581012.0 0.000816 0.028551
soil_type26 581012.0 0.004456 0.066605
soil_type27 581012.0 0.001869 0.043193
soil_type28 581012.0 0.001628 0.040318
soil_type29 581012.0 0.198356 0.398762
soil_type30 581012.0 0.051927 0.221879
soil_type31 581012.0 0.044175 0.205483
soil_type32 581012.0 0.090392 0.286743
soil_type33 581012.0 0.077716 0.267725
soil_type34 581012.0 0.002773 0.052584
soil_type35 581012.0 0.003255 0.056957
soil_type36 581012.0 0.000205 0.014310
soil_type37 581012.0 0.000513 0.022641
soil_type38 581012.0 0.026803 0.161508
soil_type39 581012.0 0.023762 0.152307
soil_type40 581012.0 0.015060 0.121791
cover_type 581012.0 2.051471 1.396504
min 25% 50% 75% max
elevation 1859.0 2809.0 2996.0 3163.0 3858.0
aspect 0.0 58.0 127.0 260.0 360.0
slope 0.0 9.0 13.0 18.0 66.0
horizontal_distance_to_hydrology 0.0 108.0 218.0 384.0 1397.0
vertical_distance_to_hydrology -173.0 7.0 30.0 69.0 601.0
horizontal_distance_to_roadways 0.0 1106.0 1997.0 3328.0 7117.0
hillshade_9am 0.0 198.0 218.0 231.0 254.0
hillshade_noon 0.0 213.0 226.0 237.0 254.0
hillshade_3pm 0.0 119.0 143.0 168.0 254.0
horizontal_distance_to_fire_points 0.0 1024.0 1710.0 2550.0 7173.0
wilderness_area1 0.0 0.0 0.0 1.0 1.0
wilderness_area2 0.0 0.0 0.0 0.0 1.0
wilderness_area3 0.0 0.0 0.0 1.0 1.0
wilderness_area4 0.0 0.0 0.0 0.0 1.0
soil_type1 0.0 0.0 0.0 0.0 1.0
soil_type2 0.0 0.0 0.0 0.0 1.0
soil_type3 0.0 0.0 0.0 0.0 1.0
soil_type4 0.0 0.0 0.0 0.0 1.0
soil_type5 0.0 0.0 0.0 0.0 1.0
soil_type6 0.0 0.0 0.0 0.0 1.0
soil_type7 0.0 0.0 0.0 0.0 1.0
soil_type8 0.0 0.0 0.0 0.0 1.0
soil_type9 0.0 0.0 0.0 0.0 1.0
soil_type10 0.0 0.0 0.0 0.0 1.0
soil_type11 0.0 0.0 0.0 0.0 1.0
soil_type12 0.0 0.0 0.0 0.0 1.0
soil_type13 0.0 0.0 0.0 0.0 1.0
soil_type14 0.0 0.0 0.0 0.0 1.0
soil_type15 0.0 0.0 0.0 0.0 1.0
soil_type16 0.0 0.0 0.0 0.0 1.0
soil_type17 0.0 0.0 0.0 0.0 1.0
soil_type18 0.0 0.0 0.0 0.0 1.0
soil_type19 0.0 0.0 0.0 0.0 1.0
soil_type20 0.0 0.0 0.0 0.0 1.0
soil_type21 0.0 0.0 0.0 0.0 1.0
soil_type22 0.0 0.0 0.0 0.0 1.0
soil_type23 0.0 0.0 0.0 0.0 1.0
soil_type24 0.0 0.0 0.0 0.0 1.0
soil_type25 0.0 0.0 0.0 0.0 1.0
soil_type26 0.0 0.0 0.0 0.0 1.0
soil_type27 0.0 0.0 0.0 0.0 1.0
soil_type28 0.0 0.0 0.0 0.0 1.0
soil_type29 0.0 0.0 0.0 0.0 1.0
soil_type30 0.0 0.0 0.0 0.0 1.0
soil_type31 0.0 0.0 0.0 0.0 1.0
soil_type32 0.0 0.0 0.0 0.0 1.0
soil_type33 0.0 0.0 0.0 0.0 1.0
soil_type34 0.0 0.0 0.0 0.0 1.0
soil_type35 0.0 0.0 0.0 0.0 1.0
soil_type36 0.0 0.0 0.0 0.0 1.0
soil_type37 0.0 0.0 0.0 0.0 1.0
soil_type38 0.0 0.0 0.0 0.0 1.0
soil_type39 0.0 0.0 0.0 0.0 1.0
soil_type40 0.0 0.0 0.0 0.0 1.0
cover_type 1.0 1.0 2.0 2.0 7.0
missing_counts = df.isna().sum()
missing_percent = (df.isna().mean() * 100).round(2)
missing_table = pd.DataFrame({
"missing_count": missing_counts,
"missing_percent": missing_percent
}).sort_values("missing_count", ascending=False)
print(missing_table.head(20))
total_missing = df.isna().sum().sum()
print("\nTotal missing values:", total_missing)
missing_count missing_percent
elevation 0 0.0
soil_type28 0 0.0
soil_type17 0 0.0
soil_type18 0 0.0
soil_type19 0 0.0
soil_type20 0 0.0
soil_type21 0 0.0
soil_type22 0 0.0
soil_type23 0 0.0
soil_type24 0 0.0
soil_type25 0 0.0
soil_type26 0 0.0
soil_type27 0 0.0
soil_type29 0 0.0
soil_type15 0 0.0
soil_type30 0 0.0
soil_type31 0 0.0
soil_type32 0 0.0
soil_type33 0 0.0
soil_type34 0 0.0
Total missing values: 0
duplicate_count = df.duplicated().sum()
print("Duplicate rows:", duplicate_count)
Duplicate rows: 0
target_col = "cover_type"
print("\nTarget value counts:")
print(df[target_col].value_counts().sort_index())
print("\nTarget proportions:")
print((df[target_col].value_counts(normalize=True).sort_index() * 100).round(2))
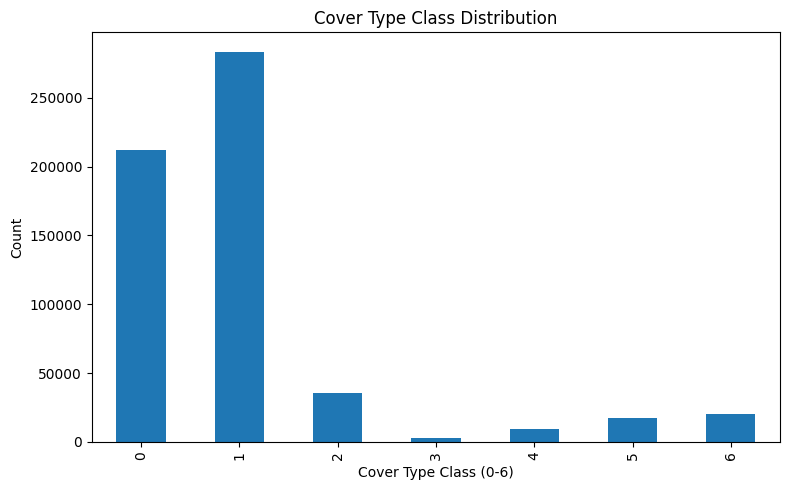
Target value counts:
cover_type
1 211840
2 283301
3 35754
4 2747
5 9493
6 17367
7 20510
Name: count, dtype: int64
Target proportions:
cover_type
1 36.46
2 48.76
3 6.15
4 0.47
5 1.63
6 2.99
7 3.53
Name: proportion, dtype: float64
# XGBoost expects class labels from 0 to number_of_classes - 1.
# Original Cover_Type labels are 1 to 7.
df[target_col] = df[target_col] - 1
print("\nTarget values after shifting from 1-7 to 0-6:")
print(df[target_col].value_counts().sort_index())
Target values after shifting from 1-7 to 0-6:
cover_type
0 211840
1 283301
2 35754
3 2747
4 9493
5 17367
6 20510
Name: count, dtype: int64
feature_cols = [col for col in df.columns if col != target_col]
# Wilderness and soil columns are already one-hot encoded.
wilderness_cols = [col for col in feature_cols if col.startswith("wilderness_area")]
soil_cols = [col for col in feature_cols if col.startswith("soil_type")]
# Continuous numeric columns are the remaining feature columns.
binary_encoded_cols = wilderness_cols + soil_cols
continuous_cols = [col for col in feature_cols if col not in binary_encoded_cols]
plt.figure(figsize=(8, 5))
df[target_col].value_counts().sort_index().plot(kind="bar")
plt.title("Cover Type Class Distribution")
plt.xlabel("Cover Type Class (0-6)")
plt.ylabel("Count")
plt.tight_layout()
plt.show()
X = df.drop(columns=[target_col])
y = df[target_col]
print("X shape:", X.shape)
print("y shape:", y.shape)
X shape: (581012, 54)
y shape: (581012,)
# First cut:
# 80% train+validation, 20% test
X_train_val, X_test, y_train_val, y_test = train_test_split(
X,
y,
test_size=0.20,
random_state=42,
stratify=y
)
# Second split:
# From train_val, create 75% train and 25% validation.
X_train, X_val, y_train, y_val = train_test_split(
X_train_val,
y_train_val,
test_size=0.25,
random_state=42,
stratify=y_train_val
)
print("Train shape:", X_train.shape, y_train.shape)
print("Validation shape:", X_val.shape, y_val.shape)
print("Test shape:", X_test.shape, y_test.shape)
Train shape: (348606, 54) (348606,)
Validation shape: (116203, 54) (116203,)
Test shape: (116203, 54) (116203,)
preprocessor = ColumnTransformer(
transformers=[
("scale_continuous", StandardScaler(), continuous_cols),
("pass_binary_encoded", "passthrough", binary_encoded_cols)
],
remainder="drop"
)
print(preprocessor)
ColumnTransformer(transformers=[('scale_continuous', StandardScaler(),
['elevation', 'aspect', 'slope',
'horizontal_distance_to_hydrology',
'vertical_distance_to_hydrology',
'horizontal_distance_to_roadways',
'hillshade_9am', 'hillshade_noon',
'hillshade_3pm',
'horizontal_distance_to_fire_points']),
('pass_binary_encoded', 'passthrough',
['wilderness_area1', 'wil...
'soil_type1', 'soil_type2', 'soil_type3',
'soil_type4', 'soil_type5', 'soil_type6',
'soil_type7', 'soil_type8', 'soil_type9',
'soil_type10', 'soil_type11', 'soil_type12',
'soil_type13', 'soil_type14', 'soil_type15',
'soil_type16', 'soil_type17', 'soil_type18',
'soil_type19', 'soil_type20', 'soil_type21',
'soil_type22', 'soil_type23', 'soil_type24',
'soil_type25', 'soil_type26', ...])])
xgb_baseline = XGBClassifier(
objective="multi:softprob",
num_class=7,
eval_metric="mlogloss",
tree_method="hist",
random_state=42,
n_jobs=-1
)
baseline_pipeline = Pipeline(
steps=[
("preprocessor", preprocessor),
("model", xgb_baseline)
]
)
print("Training Baseline XGBoost Model")
baseline_pipeline.fit(X_train, y_train)
val_pred_baseline = baseline_pipeline.predict(X_val)
baseline_accuracy = accuracy_score(y_val, val_pred_baseline)
baseline_f1_macro = f1_score(y_val, val_pred_baseline, average="macro")
baseline_precision_macro = precision_score(y_val, val_pred_baseline, average="macro")
baseline_recall_macro = recall_score(y_val, val_pred_baseline, average="macro")
Training Baseline XGBoost Model
print("\nBaseline Validation Metrics:")
print("Accuracy:", baseline_accuracy)
print("F1 Macro:", baseline_f1_macro)
print("Precision Macro:", baseline_precision_macro)
print("Recall Macro:", baseline_recall_macro)
print("\nBaseline Classification Report:")
print(classification_report(y_val, val_pred_baseline))
Baseline Validation Metrics:
Accuracy: 0.8688243849126098
F1 Macro: 0.8519775932545374
Precision Macro: 0.8843506886108257
Recall Macro: 0.8302273974629332
Baseline Classification Report:
precision recall f1-score support
0 0.86 0.84 0.85 42368
1 0.86 0.90 0.88 56660
2 0.90 0.91 0.90 7151
3 0.90 0.88 0.89 549
4 0.87 0.55 0.67 1899
5 0.85 0.82 0.84 3474
6 0.95 0.91 0.93 4102
accuracy 0.87 116203
macro avg 0.88 0.83 0.85 116203
weighted avg 0.87 0.87 0.87 116203
xgb_for_tuning = XGBClassifier(
objective="multi:softprob",
num_class=7,
eval_metric="mlogloss",
tree_method="hist",
random_state=42,
n_jobs=-1
)
tuning_pipeline = Pipeline(
steps=[
("preprocessor", preprocessor),
("model", xgb_for_tuning)
]
)
param_distributions = {
"model__n_estimators": [200, 300, 500, 700],
"model__max_depth": [4, 6, 8, 10],
"model__learning_rate": [0.03, 0.05, 0.08, 0.1],
"model__subsample": [0.7, 0.8, 0.9, 1.0],
"model__colsample_bytree": [0.7, 0.8, 0.9, 1.0],
"model__min_child_weight": [1, 3, 5, 7],
"model__gamma": [0, 0.1, 0.3, 0.5],
"model__reg_alpha": [0, 0.01, 0.1],
"model__reg_lambda": [1, 1.5, 2, 3]
}
random_search = RandomizedSearchCV(
estimator=tuning_pipeline,
param_distributions=param_distributions,
n_iter=20,
scoring="f1_macro",
cv=3,
verbose=2,
random_state=42,
n_jobs=-1
)
print("Starting Hyperparameter Tuning")
print("=" * 80)
random_search.fit(X_train, y_train)
print("\nBest CV Score:")
print(random_search.best_score_)
print("\nBest Parameters:")
print(random_search.best_params_)
Starting Hyperparameter Tuning
================================================================================
Fitting 3 folds for each of 20 candidates, totalling 60 fits
Best CV Score:
0.9208403188731179
Best Parameters:
{'model__subsample': 0.9, 'model__reg_lambda': 1.5, 'model__reg_alpha': 0.01, 'model__n_estimators': 700, 'model__min_child_weight': 3, 'model__max_depth': 10, 'model__learning_rate': 0.05, 'model__gamma': 0, 'model__colsample_bytree': 0.8}
best_model = random_search.best_estimator_
val_pred_tuned = best_model.predict(X_val)
tuned_accuracy = accuracy_score(y_val, val_pred_tuned)
tuned_f1_macro = f1_score(y_val, val_pred_tuned, average="macro")
tuned_precision_macro = precision_score(y_val, val_pred_tuned, average="macro")
tuned_recall_macro = recall_score(y_val, val_pred_tuned, average="macro")
print("Tuned Model Validation Metrics")
print("Accuracy:", tuned_accuracy)
print("F1 Macro:", tuned_f1_macro)
print("Precision Macro:", tuned_precision_macro)
print("Recall Macro:", tuned_recall_macro)
print("\nTuned Validation Classification Report:")
print(classification_report(y_val, val_pred_tuned))
Tuned Model Validation Metrics
Accuracy: 0.9509393044929993
F1 Macro: 0.9324396508506769
Precision Macro: 0.939969531757413
Recall Macro: 0.9253948395025402
Tuned Validation Classification Report:
precision recall f1-score support
0 0.96 0.93 0.95 42368
1 0.95 0.97 0.96 56660
2 0.95 0.96 0.96 7151
3 0.91 0.89 0.90 549
4 0.91 0.84 0.87 1899
5 0.93 0.92 0.93 3474
6 0.97 0.96 0.97 4102
accuracy 0.95 116203
macro avg 0.94 0.93 0.93 116203
weighted avg 0.95 0.95 0.95 116203
comparison_df = pd.DataFrame({
"model": ["Baseline XGBoost", "Tuned XGBoost"],
"accuracy": [baseline_accuracy, tuned_accuracy],
"f1_macro": [baseline_f1_macro, tuned_f1_macro],
"precision_macro": [baseline_precision_macro, tuned_precision_macro],
"recall_macro": [baseline_recall_macro, tuned_recall_macro]
})
print("Baseline vs Tuned Model Comparison")
print(comparison_df.round(4))
Baseline vs Tuned Model Comparison
model accuracy f1_macro precision_macro recall_macro
0 Baseline XGBoost 0.8688 0.8520 0.8844 0.8302
1 Tuned XGBoost 0.9509 0.9324 0.9400 0.9254
best_params = random_search.best_params_
# Remove "model__" prefix because now we pass parameters directly to XGBClassifier
clean_best_params = {
key.replace("model__", ""): value
for key, value in best_params.items()
}
final_xgb = XGBClassifier(
objective="multi:softprob",
num_class=7,
eval_metric="mlogloss",
tree_method="hist",
random_state=42,
n_jobs=-1,
**clean_best_params
)
final_pipeline = Pipeline(
steps=[
("preprocessor", preprocessor),
("model", final_xgb)
]
)
print("Training Final Model on Train + Validation")
final_pipeline.fit(X_train_val, y_train_val)
Training Final Model on Train + Validation
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('scale_continuous',
StandardScaler(),
['elevation', 'aspect',
'slope',
'horizontal_distance_to_hydrology',
'vertical_distance_to_hydrology',
'horizontal_distance_to_roadways',
'hillshade_9am',
'hillshade_noon',
'hillshade_3pm',
'horizontal_distance_to_fire_points']),
('pass_binary_encoded',
'passt...
feature_types=None, feature_weights=None,
gamma=0, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05,
max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None,
max_depth=10, max_leaves=None,
min_child_weight=3, missing=nan,
monotone_constraints=None, multi_strategy=None,
n_estimators=700, n_jobs=-1, num_class=7, ...))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| steps | [('preprocessor', ...), ('model', ...)] | |
| transform_input | None | |
| memory | None | |
| verbose | False |
Parameters
| transformers | [('scale_continuous', ...), ('pass_binary_encoded', ...)] | |
| remainder | 'drop' | |
| sparse_threshold | 0.3 | |
| n_jobs | None | |
| transformer_weights | None | |
| verbose | False | |
| verbose_feature_names_out | True | |
| force_int_remainder_cols | 'deprecated' |
['elevation', 'aspect', 'slope', 'horizontal_distance_to_hydrology', 'vertical_distance_to_hydrology', 'horizontal_distance_to_roadways', 'hillshade_9am', 'hillshade_noon', 'hillshade_3pm', 'horizontal_distance_to_fire_points']
Parameters
| copy | True | |
| with_mean | True | |
| with_std | True |
['wilderness_area1', 'wilderness_area2', 'wilderness_area3', 'wilderness_area4', 'soil_type1', 'soil_type2', 'soil_type3', 'soil_type4', 'soil_type5', 'soil_type6', 'soil_type7', 'soil_type8', 'soil_type9', 'soil_type10', 'soil_type11', 'soil_type12', 'soil_type13', 'soil_type14', 'soil_type15', 'soil_type16', 'soil_type17', 'soil_type18', 'soil_type19', 'soil_type20', 'soil_type21', 'soil_type22', 'soil_type23', 'soil_type24', 'soil_type25', 'soil_type26', 'soil_type27', 'soil_type28', 'soil_type29', 'soil_type30', 'soil_type31', 'soil_type32', 'soil_type33', 'soil_type34', 'soil_type35', 'soil_type36', 'soil_type37', 'soil_type38', 'soil_type39', 'soil_type40']
passthrough
Parameters
| objective | 'multi:softprob' | |
| base_score | None | |
| booster | None | |
| callbacks | None | |
| colsample_bylevel | None | |
| colsample_bynode | None | |
| colsample_bytree | 0.8 | |
| device | None | |
| early_stopping_rounds | None | |
| enable_categorical | False | |
| eval_metric | 'mlogloss' | |
| feature_types | None | |
| feature_weights | None | |
| gamma | 0 | |
| grow_policy | None | |
| importance_type | None | |
| interaction_constraints | None | |
| learning_rate | 0.05 | |
| max_bin | None | |
| max_cat_threshold | None | |
| max_cat_to_onehot | None | |
| max_delta_step | None | |
| max_depth | 10 | |
| max_leaves | None | |
| min_child_weight | 3 | |
| missing | nan | |
| monotone_constraints | None | |
| multi_strategy | None | |
| n_estimators | 700 | |
| n_jobs | -1 | |
| num_parallel_tree | None | |
| random_state | 42 | |
| reg_alpha | 0.01 | |
| reg_lambda | 1.5 | |
| sampling_method | None | |
| scale_pos_weight | None | |
| subsample | 0.9 | |
| tree_method | 'hist' | |
| validate_parameters | None | |
| verbosity | None | |
| num_class | 7 |
test_pred = final_pipeline.predict(X_test)
test_accuracy = accuracy_score(y_test, test_pred)
test_f1_macro = f1_score(y_test, test_pred, average="macro")
test_precision_macro = precision_score(y_test, test_pred, average="macro")
test_recall_macro = recall_score(y_test, test_pred, average="macro")
print("Final Test Set Metrics")
print("=" * 80)
print("Accuracy:", test_accuracy)
print("F1 Macro:", test_f1_macro)
print("Precision Macro:", test_precision_macro)
print("Recall Macro:", test_recall_macro)
print("\nFinal Test Classification Report:")
print(classification_report(y_test, test_pred))
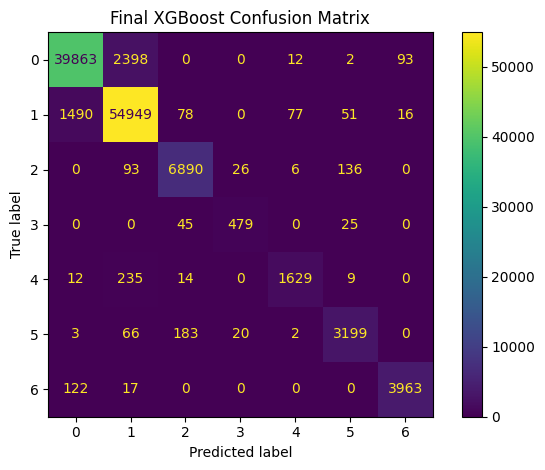
Final Test Set Metrics
================================================================================
Accuracy: 0.9549839505004174
F1 Macro: 0.9370123739255286
Precision Macro: 0.9474308399788806
Recall Macro: 0.9273853036142882
Final Test Classification Report:
precision recall f1-score support
0 0.96 0.94 0.95 42368
1 0.95 0.97 0.96 56661
2 0.96 0.96 0.96 7151
3 0.91 0.87 0.89 549
4 0.94 0.86 0.90 1899
5 0.93 0.92 0.93 3473
6 0.97 0.97 0.97 4102
accuracy 0.95 116203
macro avg 0.95 0.93 0.94 116203
weighted avg 0.96 0.95 0.95 116203
cm = confusion_matrix(y_test, test_pred)
plt.figure(figsize=(8, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot(values_format="d")
plt.title("Final XGBoost Confusion Matrix")
plt.tight_layout()
plt.show()
<Figure size 800x600 with 0 Axes>
feature_names = (
continuous_cols +
binary_encoded_cols
)
xgb_model = final_pipeline.named_steps["model"]
importance_df = pd.DataFrame({
"feature": feature_names,
"importance": xgb_model.feature_importances_
}).sort_values("importance", ascending=False)
print("=" * 80)
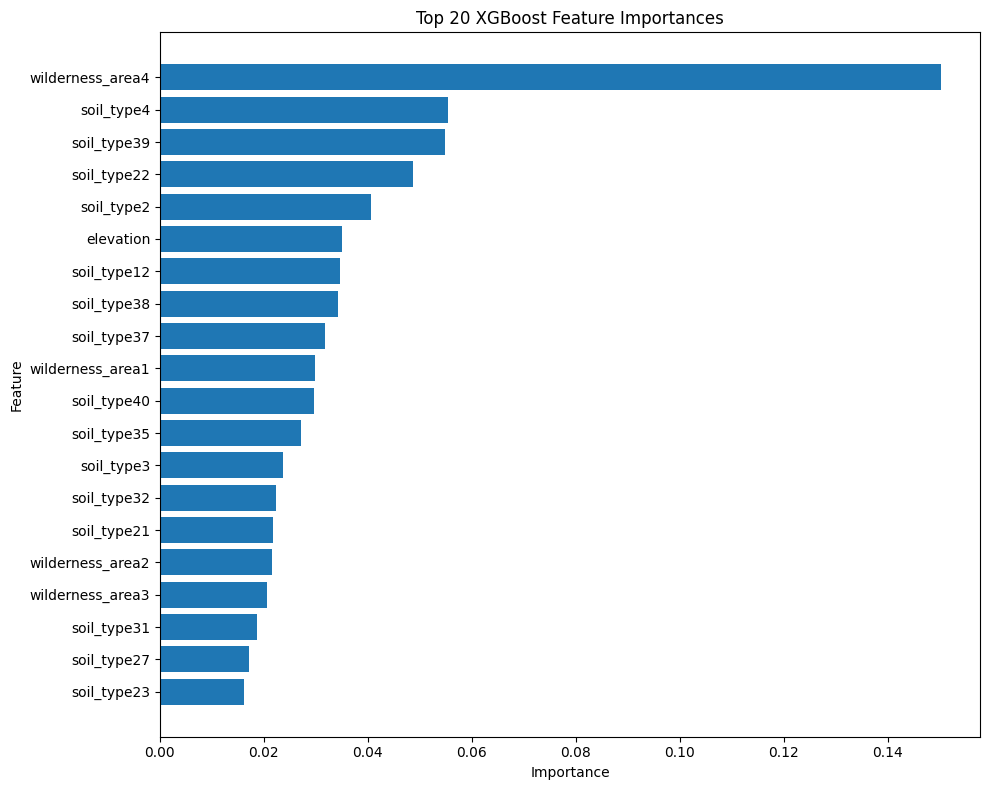
print("Top 20 Feature Importances")
print(importance_df.head(20))
plt.figure(figsize=(10, 8))
top_20 = importance_df.head(20).sort_values("importance")
plt.barh(top_20["feature"], top_20["importance"])
plt.title("Top 20 XGBoost Feature Importances")
plt.xlabel("Importance")
plt.ylabel("Feature")
plt.tight_layout()
plt.show()
================================================================================
Top 20 Feature Importances
feature importance
13 wilderness_area4 0.150222
17 soil_type4 0.055444
52 soil_type39 0.054769
35 soil_type22 0.048671
15 soil_type2 0.040670
0 elevation 0.035064
25 soil_type12 0.034678
51 soil_type38 0.034195
50 soil_type37 0.031803
10 wilderness_area1 0.029741
53 soil_type40 0.029696
48 soil_type35 0.027145
16 soil_type3 0.023744
45 soil_type32 0.022238
34 soil_type21 0.021833
11 wilderness_area2 0.021565
12 wilderness_area3 0.020666
44 soil_type31 0.018670
40 soil_type27 0.017045
36 soil_type23 0.016121